
Why I Needed a New Website and Blog
Since GDPR [3] became effective, my website wasn’t a live version of WordPress anymore, instead it was just a static snapshot of the rendered contents. This way I avoided any legal problems e.g. with Cookies or fetching external resources initiated by WordPress or any of its plugins.
The downside was, writing new blog articles became very unhandy.
Another reason I badly wanted a new website, was its dated layout from over 10 years ago, see screenshot:

Even worse, its template was based on a very old WordPress which, after all these years, became less and less compatible. Where, on a large enough screen, it was just ugly, on smartphones or other smaller screens it was hard to read because it was not responsive at all. Especially source code formatting was hideous and needed some layout work:
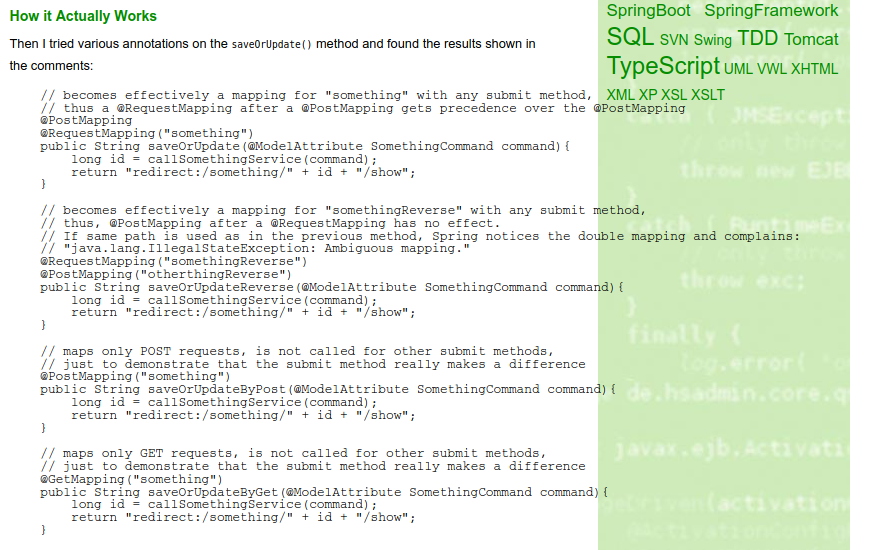
Why I chose JBake
Definitely, I wanted a static blog and website generator which fully supports AsciiDoc [4], my preferred markup language. JBake supports AsciiDoc out of the box, as well as raw HTML blog articles and Markdown [5]. It turned out that the HTML support came in handy for migrating my old blog articles from WordPress, see below for more information.
As Java is still my main programming language, JBake also looked like a good choice, just for the case I ever want to fix a bug or even add some feature.
Further, JBake supports layout languages which I am familiar with. Originally I wanted to use Thymeleaf [6] which I had already used in professional work; but as I’ve found a JBake template based on Freemarker [7] created by Manik Magar, which came very close to how I wanted my website, I chose his work [8] as the base for my layout.
The Migration
Initial Setup
At first, I upgraded some resource versions like for Fontawesome [9] of which I have a (currently perpetual) license, as well as some JavaScript libraries like jQuery ^[10] and highlight.js [11], for which I also switched to a theme with a bright background. Also, I self-hosted all resources, to avoid problems with GDPR by exposing my visitors request data to other companies.
Then I made some amendments to the layout, e.g. moving a smaller version of the top menu into the sidebar, because the original appearance was too dominant for my likes, as well as some minor changes in the templates and CSS code.
JBake supports custom metadata in contents, thus I’ve also added a summary field to some templates which even allows (some) HTML markup:
<#if (post.summary?has_content)>
<p>${post.summary?replace(">", ">")?replace("<", "<")}</p>
</#if>Unfortunately, JBake already encodes the HTML entities, and Freemarker has no unescape function.
Thus, I had to use replace, which of course is a rather heuristic approach.
Yes, it would be much better to apply AsciiDoc-to-HTML to the custom field before it’s used, maybe a nice idea to improve JBake?
Workaround for Wrong Path in Rendered HTML
The original template which I’ve used rendered the most recent blog article on the homepage. At the time of the migration process, it was this article with the screenshots of my old website.
Unfortunately, the paths of relative image URLs was wrong in the HTML because JBake, even though it was rendering /index.html was using the article path as a base, thus the images could not be found.
As a workaround, I changed the templated to show a preview of the first few articles, and thus no images paths needed to be converted.
Migrating the Contents
While I manually migrated my page content like imprint, privacy-policy, my profile and project history with some slight amendments for the new website, I wrote a little Python script to export the blog articles and convert them to the format needed by JBake:
import pathlib
import mysql.connector
from mysql.connector.cursor import MySQLCursor
def main():
try:
db = mysql.connector.connect(
host="localhost",
user="mih00_mh",
password="4-wordPress",
database="mih00_mh"
)
cursor = db.cursor(dictionary=True)
with open("wp-export.sql") as sqlFile:
cursor.execute(sqlFile.read())
for row in cursor:
export_post(row)
cursor.close()
finally:
db.close()
def export_post(row):
post_id = row["ID"]
post_date = row["post_date"].date()
post_name = row["post_name"]
post_status = row["post_status"]
post_title = row["post_title"]
post_categories = row["categories"]
post_description = row["description"]
post_keywords = row["keywords"]
post_content = row["post_content"]
target_dir = f"content/blog/{post_date.year}"
target_name = f"{post_date}-{post_name}.html"
pathlib.Path(target_dir).mkdir(parents=True, exist_ok=True)
with open(f"{target_dir}/{target_name}", "w", encoding="utf-8") as target_file:
# write redirect rules to stdout
target_path = f"/{target_dir}/{target_name}"
print(f"Redirect 301 /{post_date.year}/{post_date.month}/{post_date.day}/{post_name}$ {target_path}")
print(f"Redirect 301 /index.html@p={post_id}.html$ {target_path}")
# generate article file with metadata-header
target_file.write(f"title={post_title}\n")
target_file.write(f"date={post_date}\n")
target_file.write("type=post\n")
if post_description is not None:
target_file.write(f"summary={post_description}\n")
if post_categories is not None:
target_file.write(f"tags={post_categories}\n")
if post_keywords is not None:
target_file.write(f"keywords={post_keywords}\n")
target_file.write("status=published\n")
target_file.write("~~~~~~\n")
target_file.write("\n")
target_file.write(post_content.replace("\r", ""))
if __name__ == "__main__":
main()SELECT DISTINCT ID, post_date, post_name, post_status, post_title, post_content,
( SELECT meta_value
FROM wp_postmeta
WHERE wp_postmeta.post_id = wp_posts.ID
AND meta_key='_amt_description'
) AS "description",
( SELECT meta_value
FROM wp_postmeta
WHERE wp_postmeta.post_id = wp_posts.ID
AND meta_key='_amt_keywords'
) AS "keywords",
( SELECT group_concat(wp_terms.name separator ', ')
FROM wp_terms
INNER JOIN wp_term_taxonomy
ON wp_terms.term_id = wp_term_taxonomy.term_id
INNER JOIN wp_term_relationships wpr
ON wpr.term_taxonomy_id = wp_term_taxonomy.term_taxonomy_id
WHERE taxonomy= 'category' AND wp_posts.ID = wpr.object_id
) AS "categories",
( SELECT group_concat(wp_terms.name separator ', ')
FROM wp_terms
INNER JOIN wp_term_taxonomy
ON wp_terms.term_id = wp_term_taxonomy.term_id
INNER JOIN wp_term_relationships wpr
ON wpr.term_taxonomy_id = wp_term_taxonomy.term_taxonomy_id
WHERE taxonomy= 'post_tag' AND wp_posts.ID = wpr.object_id
) AS "tags"
FROM wp_posts
WHERE post_type = 'post'
AND post_status = 'publish'
ORDER BY post_dateTo run this script, you need to have the imported Python libraries installed, and most likely you need to use UTF-8; on Linux you can run it this way:
PYTHONIOENCODING=utf-8 python3 wp-to-jbake.pyThe script will generate the blog article files including metadata headers below content/blog.
It also prints redirect statements to stdout which you can add to your .htaccess file to redirect the former blog article paths to the new ones:
...
# redirects for URLs from my old website
Redirect 301 /2008/6/28/jsf-mit-spring-webflow /blog/2008/2008-06-28-jsf-mit-spring-webflow.html
Redirect 301 /index.html@p=74.html /blog/2008/2008-06-28-jsf-mit-spring-webflow.html
Redirect 301 /2008/7/2/resource-bundles-automatisch-konvertieren /blog/2008/2008-07-02-resource-bundles-automatisch.html
Redirect 301 /index.html@p=68.html /blog/2008/2008-07-02-resource-bundles-automatischkonvertieren.html
...Fixing Dead Links
After I had imported my old blog articles, I ran W3C Link Checker [12] which found many references to files in my former directory structure, as well as dead external links. So far I’ve only added documents from my former WordPress website, but there are still open issues. Where my older blog articles reference resources which are not available anymore, I’ll leave as it is.
Caring about Security
Next, I’ve checked my website with a Web-Security Scanner [13] which found some issues which I could fix with some entries in my .htaccess:
# security configuration
<IfModule mod_headers.c>
Header always set Strict-Transport-Security "max-age=63072000; includeSubDomains"
Header set X-XSS-Protection "1; mode=block"
Header set X-Frame-Options "DENY"
Header set X-Content-Type-Options "nosniff"
Header set Referrer-Policy "same-origin"
Header set Feature-Policy "geolocation 'self'; vibrate 'none'"
Header set Content-Security-Policy "default-src 'self' 'unsafe-inline'; script-src 'self' 'unsafe-inline'; child-src 'none'; img-src 'self' data:"
</IfModule>
Options -IndexesDepending on the libraries which you are using, you might need more open settings for Content-Security-Policy.
Open your website from the real server, not just from the file-system,
and check the console logs in the dev-tools of your browser for warnings like these:
Content Security Policy: The page’s settings blocked the loading of a resource at inline (“script-src”).
Content Security Policy: The page’s settings blocked the loading of a resource at data:image/svg+xml;charset=utf8,%3Csvg x… (“default-src”).More information about these headers you can find on htaccessbook.com [14]
For the case that you run into an HTTP code 500 error, or even better to avoid such, you can check your .htaccess on htaccesscheck.com [15].
Some Final Polish
I used a Favicon Converter [16] to generate favicon.ico, android-chrome-*.png and apple-touch-icon.png files from an image of mine, as well as the site.webmanifest.
Then I noticed that some words of my titles were too long, so the layout broke;
the article got too wide, and the sidebar got pushed to the left outside of the visible area.
I’ve fixed this issue by adding soft hyphens () to long words in the metadata titles of my articles.
Finally, I linked my error document for 404 errors:
...
# redirect unknown URLs to the generated error page
ErrorDocument 404 /404.htmlOpen Issues
For sure, this website already looks much better than my over 10 years old layout, and it finally makes adding new blog articles easy again, thus *I considered it ready for release — *Bang!
I am not done yet, though. But, is any website ever done?
First, I need to go through all my old blog articles, add the summary and fix any layout problems.
Then, I would like to keep the menu always on top, even on small screen devices; my amended menu, other than the menu in the original layout, should be small enough to fit even on a smartphone. I am also thinking about moving the rather long Tags section to a separate page with a button in the sidebar next to Blog Archive.
Also am I not yet happy with the performance, as you can see on Google PageSpeed Insights [17].
Then I know of some glitches in the CSS, e.g. that the widths and positioning of sidebar and main column seem to depend on content, and thus sometimes jump when switching pages.
Furthermore, I’ve many ideas for new features. For example, I would like to do something about multi-language. Currently, most of my website is purely in German, the same is true for older blog articles, only recent blog articles are in English. It would be too much work to translate all blog articles, but at least the website should eventually support both languages.
References
[1] WordPress: https://wordpress.org/
[2] JBake: https://jbake.org/
[3] GDPR: https://en.wikipedia.org/wiki/General_Data_Protection_Regulation
[4] AsciiDoc: https://asciidoc.org/
[5] Markdown: https://de.wikipedia.org/wiki/Markdown
[6] Thymeleaf: https://www.thymeleaf.org
[7] Freemarker: https://freemarker.apache.org
[8] Manik Mangar’s JBake template: https://github.com/manikmagar/jbake-future-imperfect-template
[9] Fontawesome: https://fontawesome.com/
[10] iQuery: https://jquery.com/
[11] highlight.js: https://highlightjs.org/
[12] W3C Link Checker: https://validator.w3.org/checklink
[13] Web-Security Scanner: https://www.immuniweb.com/websec/
[14] htaccessbook.com: https://htaccessbook.com/important-security-headers
[15] htaccesscheck.com: http://www.htaccesscheck.com/index.html
[16] Favicon Converter: hhttps://favicon.io/favicon-converter/
[17] Google PageSpeed Insights: https://developers.google.com/speed/pagespeed/insights/?hl=de&url=michael.hoennig.de
Twitter
Facebook
Reddit
LinkedIn
StumbleUpon
Email